Desde el management explicamos el Business Intelligence, las métricas de negocio (SLAs, KPIs, Cuadro de Mando Integral, Dashboards,..) y el mundo del outsourcing.
En dos líneas:maravilloso mini reportaje de la televisión pública norteamericana (PBS) sobre la visualización de datos.
Es un mini documental (dura unos 7 minutos) de la serie "Off-Books" y aunque no hay una versión doblada al castellano me ha parecido que merecía la pena compartirlo con todos vosotros ya que es a la vez increíble desde el punto de vista visual y tremendamente educativo para todos aquellos que nos dedicamos a los datos, que, a fin de cuentas, cada vez somos más en esta sociedad de la información en la que vivimos.
Muchas de las nuevas metodologias de visualización de datos que vemos en este documental seguramente se generalizarán de la mano del Big Data, en todo caso, se trata de un mundo en el que cada día nos sorprenden con nuevas ideas para ver como arte y ciencia se mezclan.
En dos líneas:durante este mes hemos estado hablando de lo qué es el Big Data, de lo que le caracteriza y de en qué áreas tiene actualmente más posibilidades de aplicarse, pero cuando hablamos de Big data ¿qué es lo que preocupa a las empresas? .
En el último año y medio han ido apareciendo cada vez más estudios sobre este tema, es normal cuando una tecnología llega a las organizaciones que surjan todo tipo de dudas y preocupaciones, de hecho a veces tengo la sensación que si cambias términos las preocupaciones son las mismas para el Big Data que para el CRM en su momento.
No se si es que los directivos son absolutamente predecibles o es que las encuestas de las consultoras hacen siempre las mismas preguntas, ¿un poco de sesgo por aquí y otro por allá?.
Un buen ejemplo de encuestas sobre las preocupaciones de los directivos a la hora de que sus empresas comiencen a trabajar con el Big Data es un estudio de Information Week de octubre de 2012, aquí tenéis un resumen de los resultados:
Las preocupaciones sobre los costes de los data warehouses tiene su origen más bien en el desconocimiento de hasta dónde tienen que llegar las inversiones dada esa pulsión que tiene el Big Data por "almacenarlo todo", además las empresas todavía no tienen muy claro que hacer con el Big Data en términos de generación de valor y lo mismo pasa con las herramientas analíticas, a muchos todavía no les convencen.
Un par de meses más tarde la consultora Aberdeen en otro estudio titulado "Data management for BI" iba por la misma dirección cuando hacía referencia a la necesidad de que las empresas dispongan de esos científicos de datos, parece que se ha iniciado una guerra por el talento.
Por esas mismas fechas Aberdeen publicaba otro estudio sobre la falta crónica de profesionales de Big Data en la industria manufacturera ("Big Data Professionals: Help Wanted") y en la que se definían las habilidades de este tipo de perfiles:
Si comparamos los estudios anteriores con otros de hace un par de años veremos que las preocupaciones de la empresa con respecto al Big Data siguen siendo las mismas, como ejemplo tomemos un estudio de 2011 publicado por The Economist Intelligence Unit titulado "Big Data - Harnessing a game Changing Asset", el cuadro que viene a continuación no da lugar a dudas:
Y supongo que aunque el Big Data es una tendencia imparable todavía quedan algunos años para que las preocupaciones de las empresas al respecto varíen mucho.
En dos líneas:hoy rompo la rutina de este mes de mayo dedicado al Big Data para anunciar que el próximo 11 de junio participaré como ponente en el Foro Profesional de Inteligencia de Negocio que tendrá lugar en el Hotel Holiday Inn de Madrid.
En el siguiente link tenéis información sobre cómo acudir al Foro Profesional de Inteligencia de Negocio, es una cita con el mundo del BI en sus distintas vertientes que ya lleva varios años celebrándose (es la novena edición), la asistencia es gratuita pero las plazas son limitadas.
En dos líneas:he tenido varias peticiones tanto vía mail como a través de redes sociales para que dedique un post a la formación que hoy en día se ofrece sobre Big Data en España, en particular sobre el framework de Hadoop.
Si además de en el Big Data estáis interesados en formaros en Business Intelligence podéis encontrar varios artículos en este blog, os dejo un link al último de los mismos.
Las opciones de formación que os voy a mostrar a continuación no pretenden ser una lista exhaustiva aunque tengo que reconocer que en España todavía no hay una gran oferta de formación en esta materia, simplemente se trata de facilitar en lo posible el trabajo de investigación que todos hemos hecho alguna vez cuando nos ha tocado invertir en formación.
Esta es la formación en Big data que he encontrado para España:
Pragsis: son partners de Cloudera y ofrecen diversos cursos sobre Big Data (essentials, desarrolladores y administradores), dichos cursos se imparten en Madrid, Barcelona y México DF y las próximas convocatorias serán este mes de junio de 2013.
Datasalt: ofrece cursos de 4 días enfocados a programadores Java, han impartido cursos en Madrid y Barcelona hasta febrero de este año, ahora los cursos son exclusivamente bajo demanda, con lo que esto conlleva.
Online Business School: tienen un Master en Big Data Management e Innovación tecnológica, comienza en noviembre de este año 2013 (dura 10 meses) y está enfocado como una introducción en el Big Data para aquellos profesionales no informáticos (matemáticos, estadísticos, economistas, directivos). Una opción para quienes busquen formación on-line y no quieran una aproximación al Big Data centrada en las herramientas.
U-Tad: imparten el título de Experto en Big Data, se imparte en Madrid y son 300 horas de formación que comienzan en octubre de 2013 y terminan en mayo de 2014, el horario es razonable, los viernes por la tarde y los sábados por la mañana, lo que me trae recuerdos de mis tiempos de alumno de master.
Global Knowledge: tienen distintos cursos on-line sobre las herramientas del framework Hadoop, la duración va desde 1 a 4 días, si os interesa os conviene tener una buena base de Linux y saber inglés ya que por lo que he podido ver en la web de este partner de formación de Cloudera los cursos están en ese idioma.
Universidad Politécnica de Cataluña: tiene un master especializado en Big data denominado Erasmus Mundus Master in Distributed Computing (EMDC), son dos años en inglés para 120 créditos ECTS, no es fácil conseguir plaza y es técnicamente muy exigente. Conviene intentar conseguir una beca.
Si no estáis seguros y queréis profundizar un poco más en el mundo del Big Data antes de tomar una decisión, podéis visitar la Big Data University con unos cursos muy básicos en inglés preparados por los distintos vendors y consultoras de la industria, lo bueno es que muchos son gratuitos.
Parecidos a los anteriores son los cursos que ofrece el vendor de Business Intelligence Pentaho.
No doy precios porque estos van variando y no quiero que os decidáis por una opción determinada en función del coste, es un factor fundamental pero no el más importante, ya que el objetivo de vuestra inversión es que la formación os proporcione mayores ingresos al mejorar vuestro perfil profesional.
Esta formación que os he comentado está por lo general orientada hacia los perfiles asociados con el trabajo con las herramientas del framework de Hadoop aunque también es muy necesaria para los "data scientists" que son los que conjugan el conocimiento matemático y de negocio necesario para sacar valor de los proyectos de Big Data.
En dos líneas:nos toca hablar de una nueva profesión que en países como EE.UU está realmente de moda, el Científico de Datos o "Data Scientist".
Para mi no hay que confundir este perfil con el del "analista de datos", la diferencia es bien sencilla y viene dada por el nivel de conocimientos estadísticos y, principalmente, por el manejo de Hadoop, en el caso del analista de datos su nivel matemático es menor y no maneja las soluciones de software asociadas al Big Data.
Así que podríamos decir que el científico de datos es el analista de datos adaptado a las necesidades del Big Data, un mix de estadístico / matemático e informático con toques de MBA, ahora se comprenden los sueldos que se pagan.
Por cierto estos chicos y chicas ya llevaban años siendo los niños mimados de muchos bancos de inversión en Wall Street, la verdad es que están detrás de mucha de la especulación en productos exóticos y derivados asociados al mercado secundario de hipotecas, el resto es historia...
Para los más curiosos recomiendo dos lecturas muy relajadas sobre el tema:
Y, por su parte, el analista de datos sería alguien con una formación en empresariales o económicas que tiene conocimientos de SQL, es un usuario muy experto de Excel y maneja con gran soltura programas de Business Intelligence y programas estadísticos como SAS o SPSS.
He de reconocer que para mucha gente en el mundillo del Business Intelligence y del Big Data, no hay diferencia, tiene cierto recorrido el chascarrillo que define al data scientist como aquel analista que vive en California, supongo que más concretamente en el área de San Francisco.
Si nos centramos en las características del perfil del científico de datos, las más importantes serían:
Gran conocimiento matemático, en especial en materia estadística al nivel necesario para trabajos científicos, de hecho hay bastantes científicos de datos que llegan al mundo de la empresa desde sectores como la bioinformática.
Una profunda curiosidad: algo que es muy propio de los científicos y mucho menos de la gente de empresa.
Capacidad de comunicación: tiene que ser capaz de transmitir sus descubrimientos a la dirección de la empresa, esto es a personas con una orientación, sensibilidad y conocimientos muy distintos a los suyos, ha de hacer hablar a los números y que cuenten su historia.
Un enfoque distinto en el análisis y resolución de los problemas.
Vamos pues avanzando un poco más en el mundo del Big Data, hemos visto su definición, las herramientas que se utilizan, el porque de la moda del Big Data y ahora nos hemos centrado en las personas que lo protagonizan en, digamos, la primera línea.
En dos líneas:En post anteriores mencionaba una de las "v" más destacadas del Big Data, la variedad de datos, dicha variedad responde tanto a su origen como a su tipología.
A pesar de que pueda parece que nos enfrentamos al típico caso de tipologías complicadas y con múltiples sub-divisiones, no hay nada de eso, de hecho se puede decir que básicamente hay dos tipos de datos en el Big Data:
Datos Estructurados
Datos No estructurados
Quizás haya lugar para mencionar brevemente una tipología intermedia, la de los datos semiestructurados (formatos como EDI, SWIFT, XML), que como en otros casos donde nos encontramos con el prefijo "semi" no son objeto de consenso en su definición.
Pero vayamos al grano:
Datos Estructurados
La definición es bien sencilla, son datos estructurados todos aquellos que tienen definida su longitud y su formato.
Y suelen ser:
Números
Fechas
Combinaciones de números y palabras, conocidas como "strings": por ejemplo el nombre de un cliente, su número de DNI, una dirección postal, un mail, etc...
Los datos estructurados son aproximadamente el 20% de los datos que encontramos en los sistemas de una empresa.
¿Y dónde los encontramos?, pues básicamente tienen su origen en los transaccionales (a saber: ERP y CRM) y suelen estar ubicados en data warehouses y datamarts. Vamos, que son los datos de finanzas, ventas, almacenes, etc...
Los consultamos generalmente a través del lenguaje SQL, en inglés Structured Query Language.
De hecho, la mayoría de soluciones de Business Intelligence y Business Analytics trabajan con este tipo de datos casi en exclusiva.
Y a pesar de lo que pueda parecer, los datos estructurados tienen un gran papel en el Big Data, lo entenderemos mejor si vemos cuál es su origen:
Datos generados por máquinas y computadoras.
Datos generados por personas, o sea, datos picados por personas en un ordenador.
Dentro de los datos estructurados generados por máquinas destacamos:
Datos procedentes de sensores: hay múltiples ejemplos como los procedentes de un GPS como el que podríamos encontrar en nuestro smartphone, las etiquetas RFID, tacómetros, contadores, equipos médicos, etc....
Web Log Data: servidores, redes, aplicaciones, etc.. generan grandes cantidades de datos estructurados.
Datos procedentes de puntos de venta: basta con pensar en un hipermercado con una cajera pasando códigos de barras por un lector.
Datos financieros: muchas operaciones bancarias y bursátiles son de datos estructurados generados automáticamente.
Los datos estructurados generados por personas también son variados y pasan desde los registros de una contabilidad en un ERP pasando por el hecho de cumplimentar un formulario en una web o incluso nuestros movimientos en uno de esos juegos on-line que ahora nos encontramos en Facebook.
No hace falta pensar mucho para ver como estos datos están asociados a otras "v" como volumen y velocidad.
Los datos estructurados son la piedra angular de las bases de datos relacionales sobre las que operan la casi totalidad de los sistemas informáticos en empresas y administración y hay que tener muy claro que el Big Data además utiliza otros tipos de bases de datos no relacionales, es el mundo No-SQL.
En los modelos relacionales la información está almacenada en tablas y las bases de datos están dotadas de un esquema, esto es, de una representación de la estructura de dicha base de datos. Así el esquema define las tablas, los campos en las tablas y las relaciones entre ambos.
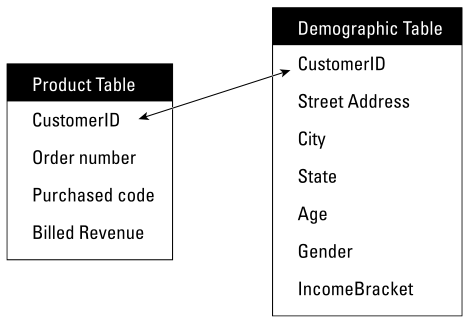
Un ejemplo sería el que proponemos a continuación, donde una tabla almacena la información de productos y la otra información sociodemográfica de los clientes que compran dichos productos:
Y la vinculación entre las tablas la da un campo clave, en este caso, el cliente (Customer ID) y cualquier consulta que se hiciese a esa base de datos sería en lenguaje SQL
Datos No Estructurados
Su definición también es sencilla, son opuestos a los datos estructurados, en el sentido de que, al contrario que aquellos, carecen de un formato específico.
Si antes decíamos que el 20% de los datos están estructurados, ahora hemos de reconocer que el 80% restante no lo está, y sólo en los últimos años disponemos de la tecnología que nos permite aprovechar dichos datos y, lo que es más importante aún, hacerlo a costes razonables.
Al igual que los datos estructurados, los no estructurados son generados bien por máquinas:
Imagenes de satélites.
Datos científicos: gráficos sísmicos, atmosféricos, etc..
Fotografía y vídeo: por ejemplo cámaras de vigilancia.
Datos de sónar y radar.
Bien por personas:
Textos incluidos dentro de los sistemas de información internos de las organizaciones: basta con pensar en documentos, presentaciones, correos electrónicos, etc...
Datos provenientes de redes sociales: a saber, Twitter, Facebook, LinkedIn, Flickr, Instragram, Tuenti, etc....
Datos provenientes de nuestros dispositivos móviles: pensemos en los mensajes que enviamos con nuestros teléfonos móviles.
Contenido de sitios web: podemos ir desde vídeos de YouTube hasta este humilde blog.
Y estos ejemplos podrían continuar y continuar...
Hay que tener muy claro que en el Big Data hay sitio tanto para los datos estructurados como para los no estructurados, para el No-SQL y para el SQL (vemos gran actividad en ese sentido), generados por personas o por máquinas.
Si pensamos en la analítica de textos que se aplica a lo que escriben los clientes de una determinada marca de coches (lo que sería un análisis de sentimiento) o de un operador de telefonía móvil, lo que se hace partir del análisis de textos (datos no estructurados) para obtener datos estructurados que nos expliquen qué está sucediendo.
En dos líneas:una de las cuestiones clave del Big Data es ¿por qué ahora?, en realidad la pregunta debería ser, ¿por qué ahora es el Big Data el hype por antonomasia en el TI?
La respuesta no está en la cantidad de datos disponible, es cierto que hay muchos más, pero siempre ha habido quienes manejaban esas cantidades inimaginables de datos, ni tampoco en el desarrollo tecnológico, la respuesta está en el dinero.
El Big Data es la consecuencia lógica de la comoditización de las tecnologías de la información, en especial aquellas asociadas con el procesamiento de datos. Es sencillo, ahora las organizaciones pueden permitirse jugar al Big Data por una mera cuestión de costes.
En dos líneas:toca desengrasar un poco y a alejarnos un rato de tanto concepto teórico y para ellos vamos a ir a la opinión de los profesionales de TI sobre el Big Data.
Aquí os dejo una infografía que resume la parte dedicada al estado actual del Big Data del estudio de Cisco titulado Cisco Connected World Technology Report, en estos estudios siempre hay que tener en cuenta que los profesionales a los que hacen la encuesta suelen ser directivos de alto nivel (CIOs) y que no siempre los cuestionarios carecen de cierto sesgo, supongo que nos entendemos.
En todo caso se reflejan algunas de las preocupaciones sobre el Big Data:
Cómo generar valor del Big Data
Cuidado con los "proyectos estratégicos"
Tenemos el presupuesto suficiente
Problemas de seguridad
Falta de analistas y de personal de TI
Falta de tiempo para analizar los datos y convertirlos en información
Hay que pasarse a la nube, ¿tendré además el suficiente ancho de banda?
En dos líneas:en el post anterior hablamos de las famosas 3 "V" del Big Data (Volumen, Velocidad y Variedad), hoy vamos a profundizar un poco más.
El concepto de Big Data es, cuando menos, bastante "abstracto" de ahí que el analista Doug Laney (actualmente en Gartner) ya hace bastantes años (en 2001) decidiese hacerlo más accesible con la idea de las 3 "V": Volumen, Variedad y Velocidad.
Volumen
En principio es lo que más atrae del Big Data: la posibilidad de procesar enormes cantidades de datos.
Además es indiscutible que de cara al análisis del información es mejor tener una gran cantidad de datos que un buen modelo que lo analice, cuanto más te acerques al concepto estadístico de "universo" menos sentido tiene trabajar con "muestras" haciendo inferencias y es precisamente eso lo que permite el Big Data.
Imaginemos que queremos predecir la demanda de un producto de nuestra portfolio, si lo hacemos teniendo en cuenta 5 factores, ¿tendremos más éxito que si lo hacemos teniendo en cuenta 200?
Hasta hace poco muchas empresas tenían grandes cantidades de datos almacenados pero no podían explotarlos, pero con el Big Data se abre una oportunidad para conseguirlo si bien hay que tener en cuenta las infraestructuras necesarias.
Asumiendo que el volumen de datos a utilizar supera las capacidades de las bases de datos relacionales más convencionales (lo cual ya es mucho para buena parte de las organizaciones) entonces básicamente tenemos dos opciones en términos de procesamiento:
Arquitecturas de procesamiento masivo en paralelo, como bases de datos y data warehouses del estilo de Greenplum (Pivotal).
Al final, la decisión viene marcada por otra de las "v", la variedad.
Lo más habitual es que un data warehouse implique esquemas predeterminados, que cuesta tiempo evolucionar, sin embargo, Apache Hadoop no obliga a ninguna condición predeterminada de los datos a procesar.
Hadoop es básicamente una plataforma para se usa para distribuir un determinado problema de procesamiento de datos entre un cierto número de servidores, facilmente cientos o incluso miles.
Los orígenes de Hadoop están en Yahoo! que lo desarrolló como una solución Open Source basándose en los trabajos pioneros de Google para la compilación de búsquedas indexadas con su framework (modelo de programación) MapReduce.
A ver si no me lio ya que no soy un experto en la materia, simplemente intento aprender y compartir, lo que hace el MapReduce de Hadoop se divide en dos partes:
La parte "Map" se ocupa de la distribución de los set de datos entre múltiples servidores y de la operación de esos datos.
La parte "Reduce" recombina los resultados obtenidos.
Para almacenar datos Hadoop utiliza su propio sistema de ficheros distribuidos (HDFS), así que lo que sucede es que 1º) se cargan los datos en HDFS, 2º) MapReduce opera los datos y 3º) el output se obtiene vía HDFS.
Es claramente un proceso batch y, por lo tanto, Hadoop no es ni una base de datos ni un data warehouse sino un apoyo analítico a los mismos.
Y no hay que olvidar que trabajar con Hadoop es todo menos fácil, se necesita de personal muy formado y experimentado, y esto no es barato.
Os dejo el vídeo de un webinar sobre Hadoop y además ¡en español!:
El ejemplo paradigmático sería Facebook, esta red social usa como base de datos MySQL de donde se toman los datos que van a Hadoop que los procesa para obtener por ejemplo las recomendaciones que facebook te ofrece en base a los intereses de tus amigos. Velocidad
La importancia de la velocidad de los datos, el ritmo al que los datos fluyen en la organización (son generados, capturados y compartidos), ha evolucionado de un modo parecido a lo que ha sucedido con el volumen de datos.
No voy a ponerme demasiado filosófico, pero es indiscutible el hecho de que Internet y las comunicaciones móviles generan cantidades ingentes de datos (vale, no hablaré de zetabytes) pero la cuestión es que las organizaciones no se pueden permitir tomar decisiones sin tener en cuenta el factor tiempo.
No todo es procesar gigantescas cantidades de información sino que también hay que conseguir un feedback y en ocasiones tiene que hacerse en "tiempo real" y para ello se utilizan tecnologías de streaming de datos.
Basta con pensar en las necesidades asociadas al uso de aplicaciones para smartphones o al juego on-line, esta claro que cuanto más veloz sea el feedback mayor será la ventaja competitiva.
En esta "v" tenemos por un lado a IBM con su InfoSphere Streams y por otro a los chicos del Open Source con sus soluciones bastante menos pulidas como son los frameworks de Twitter (Storm) y de Yahoo! (S4).
Variedad
Hay que reconocer que es raro que los datos se nos presenten siempre de una forma clara y ordenada bien lista para su procesamiento, es un lugar común en el Big Data el hecho de que los datos vengan de fuentes muy diversas y que no entren dentro de la tipología que exigen los esquemas relacionales.
Estamos hablando de texto en redes sociales, imagenes, vídeo, audio o datos de sensores en bruto, nada de esto está preparado para la típica integración de datos en una aplicación.
Nos adentramos pues en la bifurcación más importante en la tipología de los datos: estructurados y no estructurados, este asunto lo trataremos independiente en el próximo post.
Un uso habitual del Big Data es tomar datos no estructurados para extraer significado de los mismos, bien para el consumo por parte de personas bien como input para aplicaciones, la cuestión aquí es que cuando se pasa de datos en bruto a datos estructurados ya procesados hay mucha información que se pierde (y ya no se puede recuperar) de ahí un "refrán" de la gente del Big Data:
Cuando puedas, guardalo todo.
A pesar de su gran popularidad e implantación no todo los tipos de datos funcionan bien en bases de datos relacionales basta con pensar en documentos codificados como XML o en los gráficos que tanto abundan en las redes sociales, a los primeros les convienen más bases de datos como Marklogic y a los segundos como Neo4J.
Además los esquemas de las bases de datos relacionales son muy rígidos mientras que en los entornos No-SQL si se encuentra la flexibilidad que se necesita cuando "exploramos" datos.
Conclusiones
Esta claro que estas 3 "v" son una simplificación, si se quiere, una herramienta de marketing y para mi es cierto, pero me asalta la duda de si merece la pena dejar un concepto como el del Big Data únicamente sujeto a definiciones muy técnicas sólo al alcance de unos pocos.
Aquí tenéis un ejemplo de ese "marketing" en forma de un vídeo presentado en la SAS Analytics Conference en octubre del año pasado, les quedó muy chulo:
En dos líneas:lo prometido es deuda así que comenzamos el mes del Big Data en nuestro blog, y, para abrir boca, me atrevo con una definición de Big Data.
La verdad es que afronto este "compromiso" con el Big Data desde una postura ambivalente, reconozco el hecho de que estamos ante un claro caso de hype y, por otra parte, me fascina el impacto que ya está teniendo en nuestras vidas.
Espero que dentro de 30 días tenga más clara mi postura, pero es mejor dejar las divagaciones e ir al grano.
Definición de Big Data
Es cualquier fuente de datos (data source) que al menos comparte las siguientes características:
Supone Volumenes de datos extremadamente grandes, muy difíciles de procesar con las tecnologías más utilizadas hoy en día.
Datos que se han de procesar a enorme Velocidad.
Datos extremadamente Variados en su origen y tipología.
Hay quien más que de "data source" hablaría de "data set" (conjunto de datos) o incluso de "analysis set", pero no nos dispersemos.
Se trata pues, de permitir a las organizaciones reunir, almacenar, gestionar y tratar grandes volumenes de datos a:
La velocidad adecuada
En el momento adecuado
Para generar el conocimiento / insight adecuado
No encontramos pues con las famosas "Tres V del Big Data": Volumen, Variedad y Velocidad.
Se podría añadir una cuarta "v", la que se refiere a la Veracidad de los datos, aquí se abre cierto espacio para la polémica, pero como tengo muchos posts por delante lo dejo ahí por el momento.
Y un estadístico te hablaría de una quinta: Variabilidad
Además hay que lograr todo esto de un modo eficaz y, sobre todo, eficiente desde un punto de vista de los costes y, obviamente, ayudando a la toma de decisiones que generen Valor, vaya, ¡otra "v"!
Sin esto último el Big Data simplemente no tendría sentido más allá de aplicaciones de ciencia básica.
Se trata de una definición ambigua, de hecho se podría aplicar a tecnologías como el Business Intelligence, por lo que nos toca profundizar más.
En primer lugar hay que aclarar una cosa, el Big Data en realidad no es una tecnología nueva e independiente de la evolución que hemos vivido en los últimos 50 años en la administración de datos (data management), es el nombre de una tendencia que cada vez tiene más resonancia y que es precisamente el fruto de dicha evolución.
Así que el que nos hable de tecnología "disruptiva" nos está vendiendo una moto, humo, o como lo queráis llamar.
En lo que se refiere a las 3 V del Big Data si os fijáis en el gráfico de arriba veréis que hablamos de:
Volumen: hablamos de Terabytes camino de Petabytes
Velocidad: Datos en Tiempo Real, esto es más complejo de lo que parece, es una cuestión de "ritmos" ya que no todos los datos se registran y procesan a la misma velocidad esto no depende únicamente de la tecnología, habría que hablar de "eventos de datos".
Variedad: se incorporan datos no estructurados.
Por mi parte por hoy es suficiente, tal y como voy a hacer en los posts que vaya escribiendo sobre este tema os proporciono links y vídeos que espero resulten interesantes y de utilidad.